

 Übersicht
Übersicht|
Halloween-Update: Automail Automail dient zum automatisierten Versenden von Mails. Man kann also ein Formular anbieten, bei dem sich Anwender mit Namen und Mail-Adresse eintragen. An diese werden dann zeitgesteuert Mails verschickt. Doubleoptin und jederzeitiges austragen ist natürlich möglich. Diese Funktion wird von Info-Marketern gerne eingesetzt. Es würde hier aber zu weit führen, das hier genauer zu erklären. Man legt eine Vorlage automail/ini an. Dort steht z.B. [set_1] template=ehrliche-lebensmittel inform_new=horst@klier.net inform_check=horst@klier.net inform_stop=horst@klier.net inform_sender=info@leben-ohne-diaet.de Dabei ist die "1" hinter dem set_ die Id. Die Einträge darunter sind dieser einen Id zugeordnet. Es muss keine Zahl sein und auch nicht durchnummeriert werden. Das ist hier nur zufällig eine 1. template gibt an, unter welchem Namen die weiteren Vorlagen dazu angelegt sind. Die inform_xxx sind Mail-Adressen. new, check und stop sind dabei reine Informationsmails, die bei Neuanmeldungen, Doubleoptin-Bestätigungen und Abmeldungen verschickt werden können, der sender ist der Absender der verschickten Mails. Zu dem Namen "ehrliche-lebensmittel" gibt es dann weitere Vorlagen: automail/ehrliche-lebensmittel/ini headline=Gesund Abnehmen ohne Diät headline ist die Überschrift. Diese kann man bei weiteren Vorlagen als Platzhalter verwenden. targetpage gibt eine Zielseite an, bei der das MOdul später eingebunden sein muss um An- und Abmeldungen anzunehmen. mails ist die Anzahl an Nachrichten, die verschickt werden. Darunter sind die jeweiligen Zeiten in Stunden angegeben, wann die Mails versendet werden.targetpage=http://www.leben-ohne-diaet.de/programm/o.prg?pos=Automail mails=5 hours_1=0 hours_2=24 hours_3=48 hours_4=72 hours_5=96 automail/ehrliche-lebensmittel/mail-opt-in tdbmail Das ist die Nachricht, die zum Double-Opt-In auffordert. Die Platzhalter dürften klar sein, oder?{Mail} horst@klier.net Leben ohne Diät - Bitte bestätigen Sie den Empfang Hallo {Name}, Vielen Dank für Ihr Interesse! Sie müssen den kostenlosen Empfang noch bestätigen. Benutzen Sie dafür den folgenden Link: {linktoactivate} automail/ehrliche-lebensmittel/main {success} Das ist also die Vorlage für Formular und Fehlermeldungen. Die einzelnen Abschnitte haben sprechende Namen. Was man beachten sollte ist, dass bei der Form-Action hinten die id angehängt wird. Das muss eben genau die sein, die in der automail/ini steht. Das Sourceid ist zum Durchschleifen einer Tracking-Information. Man will ja wissen, woher die Anmeldungen kommen.<h1 style="color:#ffffff;">Vielen Dank.</h1><br /> <br />Sie erhalten in wenigen Minuten eine Mail, in der Sie den Empfang mit einem Klick bestätigen müssen.<br /> {/success} {error} <h1 style="color:#ff4444;">Fehler</h1><br /> <br />Es ist ein Fehler aufgetreten. Bitte prüfen Sie Ihre Angaben.<br /> {/error} {form} <form action="{link="type:dynamic;/Automail"}&id=1" method="post"> <table border="0" cellpadding="2" cellspacing="2"> {nameerror} <tr> <td></td> <td style="color:#880000;">Bitte geben Sie Ihren Vornamen an. </td> </tr> {/nameerror} <tr> <td><b>Vorname:</b> </td> <td><input type="text" name="Name" size="66" value="{Name}" class="text" style="width:145px;"></td> </tr> {mailerror} <tr> <td></td> <td style="color:#880000;">Bitte geben Sie Ihre Email-Adresse an. </td> </tr> {/mailerror} <tr> <td><b>Email:</b> </td> <td><input type="text" name="Mail" size="66" value="{Mail}" class="text" style="width:145px;"></td> </tr> <tr> <td> </td> <td colspan="1" align="left"> <input type="hidden" name="Sourceid" value="{Sourceid}"> <input type="submit" value="Eintragen" name="OK" class="button"></td> </tr> </table> </form> {/form} {opt-in-success} <h1 style="color:#ffffff;">Vielen Dank.</h1><br /> <br />Sie haben sich erfolgreich für den kostenlosen Empfang angemeldet.<br /> {/opt-in-success} {opt-in-error} <h1 style="color:#ff4444;">Fehler</h1><br /> <br />Ich kann Sie nicht eintragen. Ihre Adresse wurde nicht gefunden oder der Code stimmt nicht. Haben Sie sich vielleicht bereits an- und wieder abgemeldet?<br /> {/opt-in-error} {opt-out-success} <h1 style="color:#ffffff;">Schade.</h1><br /> <br />Sie wurden ausgetragen. Sie erhalten keine weiteren Nachrichten.<br /> {/opt-out-success} {opt-out-error} <h1 style="color:#ff4444;">Fehler</h1><br /> <br />Ich kann Sie nicht austragen. Ihre Adresse wurde nicht gefunden oder der Code stimmt nicht. Haben Sie sich vielleicht bereits abgemeldet?<br /> {/opt-out-error} automail/ehrliche-lebensmittel/mail-1 tdbmail Das ist die erste Mail, 5 entsprechende gibt es. Diese müssen einfach durchnummeriert sein.{Mail} horst@klier.net Leben ohne Diät - Teil 1 - Meine Geschichte Hallo {Name}, hier kommt auch schon der erste Teil. ... ________________________________________________________ Wenn Sie keine Nachricht mehr erhalten wollen, klicken Sie einfach den folgenden Link {linktounsubscribe} ________________________________________________________ Dieser Newsletter wird herausgegeben von Horst Klier, Schwabenstr. 30, 91126 Schwabach Tel: 09122 632211 Web: http://www.leben-ohne-diaet.de Mail: horst@klier.net Das wars? Nein. Automail soll ja automatisch Mails versenden. Deswegen brauchen wir einen Eintrag in der schedul.ini: program_14=automail.prg >>../logfiles/automail.log dir_14=../custprg next_start_14=27.10.2009 10:10 every_min_14=10 Und eingebunden werden muss das Modul auch noch. In der ini steht eine Targetpage. Dort muss das Modul auf jeden Fall eingebunden werden: {execmacro="automail"} Mehr muss nicht auf die Seite. Weil das nur die Zielseite ist. Theoretisch müsste man dafür keine extra Seite anlegen, aber ich finde es besser, wenn keine störenden Elemente zu sehen sind.Zur Einbindung des Formulars benutzt man {execmacro="automail" param="1;sourceid=Tracking"} Die 1 ist wieder die Id. Die SourceId ist optional und dient dazu, hinterher zu wissen, woher die Eintragung gekommen ist.BeispielUnd weil ich weiß, dass auch das wieder viel komplizierter klingt, als es ist, lade ich sie zu einem Beispiel ein. Unter http://www.leben-ohne-diaet.de/text/buch/bestellen.html finden Sie unten ein Formular "Noch nicht überzeugt?". Wenn Sie sich dort eintragen, sehen Sie den Automailer in Aktion.Dieser Artikel wurde veröffentlicht am 31.10.2009 um 10:15 Uhr. Noch kein Kommentar. Halloween-Update: Newsletter Die Neuerung im Newsletter ist eher etwas für Profis. Falls man eine umfangreichere Benutzerverwaltung verwendet, hat man dort oft direkt die Verwaltung, ob der Nutzer einen Newsletter empfangen will oder nicht. Das Feld, wo man das festlegt, kann man nun einfach in der newsletter.ini angeben. Beispielsweise [user] cms_usermanagement=Newsletter Das bedeutet, dass es ein Feld Newsletter (Boolean) in der usr_user geben muss. Beim versenden eines Newsletters bekommen alle Nutzer dort eine Mail, bei denen in diesem Feld eine 1 steht. Dieser Artikel wurde veröffentlicht am 30.10.2009 um 10:15 Uhr. Noch kein Kommentar. Halloween-Update: Formmail Der Formmailer kann nun mehrere Mails absenden. Die Vorlage für die erste ist nach wie vor formmail/abc/mail. Die weiteren werden dann mit
abc steht natürlich für die entsprechende Vorlage, je nach Parameter. Dieser Artikel wurde veröffentlicht am 29.10.2009 um 10:15 Uhr. Noch kein Kommentar. Halloween-Update: Kommentare Die Kommentarfunktion wurde leicht überarbeitet. Im Grunde gibt es ein Feld in der Datenbank, das den Nutzer speichert, falls einer angemeldet ist. Bei der Ausgabe kann man mit {User} abfragen. Beispielsweise kann mit einem Konstrukt wie {if="{User}=0"}background-color: #eeeeee;{end} die Hintergrundfarbe von Kommentaren bei angemeldeten Benutzern farbig hinterlegt werden. Um bei der Eingabe diesen das Captcha zu sparen, kann das Formular comment/form mit Javascript arbeiten. Es gibt unter programm ein kleines Hilfstool, was Userinformationen der aktuellen Session zurückliefert. Das kann per httpxmlrequest angesprichen werden. Klingt kompliziert? Hier ein Beispiel: <a name="comform"></a><span class="headline">Neuen Kommentar verfassen:</span> <form action="{action}&#message" method="POST"> <table callpadding="0" cellspacing="0" border="0"> <tr><td>Name:</td><td><input type="text" id="fieldName" name="Name" value="{Name}" size="50"></td></tr> <tr><td>Email:</td><td><input type="text" id="fieldMail" name="Mail" value="{Mail}" size="50"> <span class="small">(wird nicht veröffentlicht)</span></td></tr> <tr><td valign="top">Website:</td><td><input type="text" id="fieldWebsite" name="Website" value="{Website}" size="50"> <span class="small">(optional)<br /> Achtung Möchtegern-SEOs: Kommerzielle Websites, die in keinem Bezug zum Thema des Beitrags stehen, werden gelöscht. Deeplinks sind mir immer suspekt.</span></td></tr> <tr><td valign="top">Text:</td><td><textarea name="text:Text" rows="10" cols="60">{Text}</textarea></td></tr> <tr><td> </td><td><input type="checkbox" name="InformAboutNewComments" {InformAboutNewComments}> Bei neuen Kommentaren per Email benachrichtigen</td></tr> <tr><td> </td><td><input type="checkbox" name="store" {store}> Angaben (Name, Email, Website) speichern</td></tr> <tr id="captcha"><td valign="top"><br>Code:</td><td>{captchaimage}<br /><input type="text" name="captcha"> (Bitte Code von oben eingeben)</td></tr> <tr><td> </td><td><span class="small">Hinweis: Mit dem Absenden Ihres Kommentars willigen Sie ein, dass der angegebene Name, Ihre E-Mail-Adresse und die IP-Adresse, die Ihrem Internetanschluss aktuell zugewiesen ist, im Zusammenhang mit Ihrem Kommentar gespeichert werden. Die E-Mail-Adresse und die IP-Adresse werden natürlich nicht veröffentlicht oder sonst weitergegeben.<br /></span> <input type="submit" name="send" value="Absenden"></td></tr> </table> </form> <script> // XML-Transfer function XMLInitCommentForm() { // cFunction: load / save var http_request = false; var URL = "/programm/getuser.prg?"+Math.ceil(Math.random()*1000); if (window.XMLHttpRequest) { //Mozilla http_request = new XMLHttpRequest(); } else { if (window.ActiveXObject) { // IE try { http_request = new ActiveXObject("Msxml2.XMLHTTP") } catch(e) { try { http_request = new ActiveXObject("Microsoft.XMLHTTP") } catch(e) {} } } } if (!http_request) {alert('Ihr Browser unterstützt diese Funktion (XMLHttpRequest) leider nicht! '); return false;} http_request.onreadystatechange = function() {XMLProcessCommentForm(http_request)} http_request.open('GET',URL,true); http_request.setRequestHeader('content-type', 'text/plain'); http_request.setRequestHeader('charset', 'iso-8859-1'); http_request.send(); } function getCookie(name){ // Cookie-Wert auslesen var i=0 var suche = name+"=" while (i<document.cookie.length){ if (document.cookie.substring(i, i+suche.length)==suche){ var ende = document.cookie.indexOf(";", i+suche.length) ende = (ende>-1) ? ende : document.cookie.length var cook = document.cookie.substring(i+suche.length, ende) return unescape(cook) } i++ } return '' }; function ReadLn(cText){ var nEnd=0; var c=''; nEnd=cText.indexOf('\n',0); if(nEnd!=-1){ c=cText.slice(0,nEnd); }else{ c=cText; } if(c.indexOf('\r')>=0){c=c.slice(0,c.indexOf('\r'))}; // Windows-Kombatibilität mit CR+LF statt nur LF return c } function DelLn(cText){ var nEnd=0; var c=''; nEnd=cText.indexOf('\n',0); if(nEnd!=-1){ c=cText.slice(nEnd+1); }else{ c=''; } return c } function XMLProcessCommentForm(http_request) { var cResponse=''; try { if (http_request.readyState == 4) { //abgeschlossene übertragung if (http_request.status == 200 || http_request.status == 0) { // Code OKAY cResponse=http_request.responseText; var cUser=''; var cUsername=''; var cMail=''; cUser=ReadLn(cResponse); cResponse=DelLn(cResponse); cUsername=ReadLn(cResponse); cResponse=DelLn(cResponse); cMail=ReadLn(cResponse); // Wenn User, dann Captcha ausblenden if(cUser!='0'){document.getElementById('captcha').style.display='none';} // Wenn Felder leer, dann mit Cookie besetzen if (document.getElementById('fieldName').value+document.getElementById('fieldMail').value+document.getElementById('fieldWebsite').value==''){ document.getElementById('fieldName').value=getCookie('cName'); document.getElementById('fieldMail').value=getCookie('cMail'); document.getElementById('fieldWebsite').value=getCookie('cWebsite'); } // Wenn immer noch leer, mit Userinfo aus Session besetzen if (document.getElementById('fieldName').value==''){ document.getElementById('fieldName').value=cUsername; } if (document.getElementById('fieldMail').value==''){ document.getElementById('fieldMail').value=cMail; } } else { alert("Übertragungsfehler Status "+http_request.status) } } } catch(E) { //alert("Fehler: "+E.message) } } XMLInitCommentForm(); </script> In diesem Beispiel wird geprüft ob ein Nutzer angemeldet ist. Falls ja, wird sein Nutzername und Mail in die Felder eingetragen und das Captcha ausgeblendet. Falls der Nutzer in die Felder andere Werte eingibt, können diese immer noch per Cookie gespeichert werden und werden dann in Zukunft benutzt. Eine andere Lösung kann man z.B. hier sehen. Da ist nur noch angemeldeten Nutzern das Kommentieren erlaubt. Der Name wird fest vorgegeben, eine extra Website kann nicht übergeben werden. Dafür werden dann die Kommentatornamen mit dem Nutzerprofil (was es auf der Seite eben gibt) verlinkt. Dieser Artikel wurde veröffentlicht am 28.10.2009 um 10:15 Uhr. Noch kein Kommentar. Halloween-Update: Fehlerprüfung Wie angekündigt nun weitere Informationen zum Update. Die größte Änderung ist die integrierte Fehlerprüfung. Dabei wird bei jedem Seitenaufruf eine Datenbank befüllt, mit Angaben zu allen verwendeten Bestandteilen. Das ist also z.B. eine benutze Grafik, ein Dateidownload, Vorlagen usw.. Auch interne und externe Links. Diese Informationen werden jeweils mit einem Zeitstempel abgelegt. Der Sinn davon ist, dass man so leicht feststellen kann, welche Elemente in welcher Seite benutzt werden und wann. Hat man dynamischen Code, der erst einen konkreten Bildnamen ergibt, ist das auch kein Problem. Nützlich ist das dann direkt, wenn Fehler gefunden werden. Also etwa ein Link auf eine Seite eingebunden wird, die nicht existiert. Oder ein Grafikname falsch geschrieben wird. Unter Tools gibt es den neuen Punkt "Fehlerprüfung", der solche Dinge anzeigt. Wobei die Standardeinstellung Fehler erst beim dritten Auftreten anzeigt. Man muss das aber auch nicht ständig im Blick behalten, da der rsscheck entsprechende Probleme meldet. Externe Links werden getrennt davon behandelt. Diese landen in einer extra Datenbank und werden von Zeit zu Zeit geprüft. Tritt dort über einen längeren Zeitraum bei einer Adresse ein Fehler auf, so wird auch das gemeldet. Über Tools/LinkCheck wird das angezeigt und kann direkt bearbeitet werden. D.h. bei einem Fehlerhaften Link reicht ein Klick, um ihn aus dem Inhalt einer Seite zu entfernen. Oder man ignoriert die Meldung für einen bestimmten Zeitraum. Diese Funktionalität dürfte absolut einmalig sein. Ein CMS was direkt Links prüft und eine extra Oberfläche zur Bearbeitung mitbringt. Ehrlich gesagt gibt es das auch nur, weil ich im Blog ohne Diät [Link entfernt, weil Linkziel leider nicht mehr verfügbar] tausende alter Links hatte. Einrichten: Da sehr viel im Hintergrund passiert, werden 3 neue Einträge in der schedul.ini fällig. Die Eintragsnummern bitte entsprechend anpassen: program_11=cms_linkcheck.prg -v >>../logfiles/linkcheck.log dir_11=../schedul next_start_11=27.10.2009 09:15 every_min_11=9 program_12=linkcheck.prg dir_12=../custprg next_start_12=28.10.2009 00:00 every_min_12=1440 program_13=usagecheck.prg dir_13=../custprg next_start_13=28.10.2009 00:00 every_min_13=1440 cms_linkcheck prüft die Links. Dabei arbeitet es mit einem internen Cache. D.h. es wird nicht unendlich viel Traffic erzeugt. linkcheck und usagecheck zählen die aktuellen Fehler und schreiben diese in eine Ini-Datei. Das ist für den rsscheck wichtig. Diese Prüfung nur einmal am Tag reicht und spart Resourcen. Da die Datenbanken mit Zeitstempel arbeiten um auch dynamische Inhalte bearbeiten zu können, sorgt der trashman für eine Bereinigung alter Einträge. Hierfür sind folgende Einträge notwendig: [Bases] ... Name_8=../sysbase/cms_usage.dat MaxAge_8=86400 DateField_8=Last TimeField_8=Last Name_9=../sysbase/cms_linkcache.dat MaxAge_9=86400 DateField_9=Lastchecked TimeField_9=Lastchecked Auch wenn dieser Aufwand manchem übertrieben erscheinen mag, es lohnt sich. Fehler passieren und Links sind nicht mehr erreichbar. Man ändert an einer Stelle eine Kleinigkeit und vergisst, dass es an einer Position auch eine Rolle spielt. Mit der integrierten Prüfung merkt man solche Fehler schnell. Das ergibt eine gut gepflegte Website. Das wird auch von Google belohnt. Später mal ist geplant, direkt bei den Grafiken oder Vorlagen anzuzeigen, welche Seiten diese benutzen. Ich würde mich über Feedback zu dieser Funktionalität sehr freuen. Gerne beantworte ich auch Fragen. Mir ist schon bewusst, dass es etwas schwer zu verstehen ist, wenn man es nur liest. Wenn es aber mal integriert ist, muss man garnicht weiter darüber nachdenken. eforia sagt einfach hin und wieder mal Bescheid, wenn ihr Fehler auffallen. Dieser Artikel wurde veröffentlicht am 27.10.2009 um 10:15 Uhr. Noch kein Kommentar. Halloween-Update  In Kürze veröffentliche ich ein Update für den ewm5. Darin sind doch einige Neuerungen, zu denen es mehr zu sagen gibt. Deswegen will ich die nächsten Tage vorab über die einzelnen Dinge schreiben, bevor das Update bereit gestellt wird. Und weil Ende der Woche eben auch Halloween ist, gibt das ja gleich den Titel vor. 8-) In Kürze veröffentliche ich ein Update für den ewm5. Darin sind doch einige Neuerungen, zu denen es mehr zu sagen gibt. Deswegen will ich die nächsten Tage vorab über die einzelnen Dinge schreiben, bevor das Update bereit gestellt wird. Und weil Ende der Woche eben auch Halloween ist, gibt das ja gleich den Titel vor. 8-)
Dieser Artikel wurde veröffentlicht am 26.10.2009 um 10:45 Uhr. Noch kein Kommentar. SEO-Tipp: 404 abfangen Heute mal ein kleiner SEO-Tipp und wie man diesen in der Praxis mit eforia umsetzt. Wie heutzutage jedem Webmaster bekannt sein dürfte, sind Links für eine gute Position bei den gängigen Suchmaschinen enorm wichtig. Dumm, wenn jemand die eigene Seite verlinkt, aber versehentlich einen Tippfehler in der Adresse hat. Ein beliebtes Problem sind Kommentare oder Foren, bei denen URLs automatisch in Links gewandelt werden, wenn man die Adresse in Klammern angibt. Also z.B. Ich benutze eforia als CMS (http://www.eforia.de/index.html)und die Software extrahiert als Link nicht http://www.eforia.de/index.htmlsondern http://www.eforia.de/index.html)Das Resultat ist ein "404 Not Found"-Fehler. Der Link ist verloren. Nun kann man die eigenen Webserver-Logfiles nach 404-Fehlern durchforsten. Das machen Techniker sicher auch gerne, aber wenn man keinen Zugriff darauf hat, gibt es auch eine andere Methode solche Seiten zu finden. Nämlich über die Google Webmaster-Tools. Hat man eine Seite dort angemeldet, findet sich unter dem Punkt Diagnose/Crawling-Fehler auch die Option Nicht gefunden. 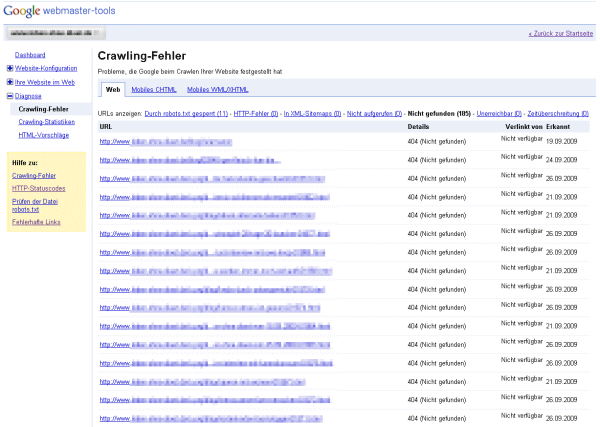 Dort erhält man eine Liste von Adressen, die Google versucht hat zu crawlen, aber nicht gefunden hat. Manchmal wird auch die Ursprungsseite angezeigt, dann könnte man sich evtl. an den Linksetzer wenden und um Korrektur bitten. Oft ist das aber nicht möglich. Deswegen legen wir selbst Hand an. Solange zumindest die Domain stimmt, kommen die Besucher ja zu unserer Seite. Wir müssen ihnen nur den Weg zeigen. Das geht mit einem Redirect ganz einfach. Wer einen Apache als Webserver verwendet - also im Prinzip jeder 8-) - kann über eine .htaccess-Datei Redirect-Regeln anlegen. Ich hatte darüber schon vor 2 Jahrenmal etwas dazu geschrieben. Tipp: Mit ewm5 kann man sich die Bearbeitung der .htaccess-Datei erleichtern. Einfach in der cms.ini unten anfügen: und schon kann direkt über Tools/Konfiguration/Editor für INI-Dateien auf die .htaccess zugegriffen werden. 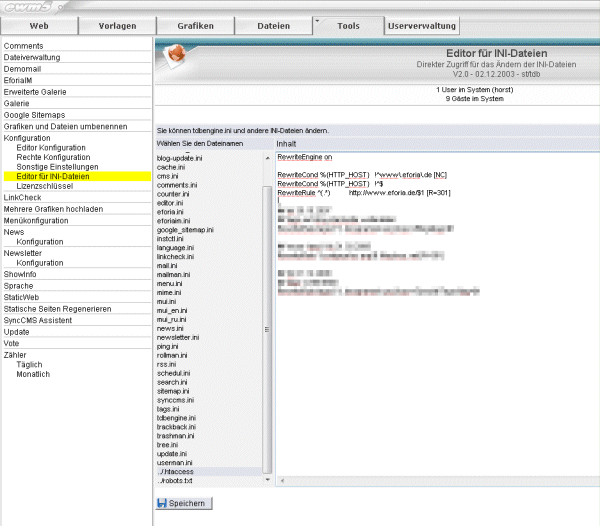 Was schreibt man nun da rein?Ganz oben muss zuerst mal die sogenannte Rewrite-Engine gestartet werden. Das macht man mit einemDann kommen die einzelnen Regeln. Für das obige Beispiel mit der Klammer am Ende würde es z.B. so aussehen: Wenn man davon auch nichts versteht außer, dass die \ das jeweils nächste Zeichen maskieren - also es wird dann so verstanden wie es aussieht und hat keine Sonderfunktion, wie es ein . und eine ) sonst hätten - versteht man schon das Prinzip. Man kann mit regulären Ausdrücken arbeiten und z.B. so auch eine Regel erstellen, die alle ) am Ende entfernen würde. Davon rate ich aber eher ab. Das sollte nur in Einzelfällen gemacht werden, wenn sich das Problem anderweitig wirklich nicht beheben lässt. Zum Schluss noch ein Beispiel, für einen simplen Tippfehler in der URL. Die korrekte Adresse wäre http://www.eforia.de/blog/index.htmlaber jemand hat http://www.eforia.de/block/index.htmlverlinkt. Die RewriteRule muss dann so aussehen: Einfach, oder? Die Regeln werden übrigens einfach hintereinander geschrieben. Das ReWriteEngine on ist nur einmal notwendig. Man kann auch noch Bedingungen einfügen und auch mehr als nur 301er Weiterleitungen. Aber dafür gibt es jede Menge Stoff im Netz. Und bitte keine Panik, wenn es mal nicht auf Anhieb klappt. Selbst langjährige gestandene Programmierer haben immer wieder Probleme. Da muss man einfach mal ein wenig damit spielen, dann geht das schon. Wer Fragen hat, darf sich gerne an mich wenden. Ich habe doch schon etwas Erfahrung auch mit komplexeren Rewrite-Spielereien. 8-) Achja, das ist übrigens etwas, was Google einem nicht übel nimmt. Ganz im Gegenteil. Man verhindert damit ja eine Fehlermeldung beim Nutzer. Das verbessert dessen "Experience". Das findet Google toll! Dieser Artikel wurde veröffentlicht am 05.10.2009 um 14:04 Uhr. Noch kein Kommentar. Backup Hilfe Ich verwende schon länger eine simple Methode um ein nächtliches Backup zu erstellen, welches auch mehrere Tage rückwirkend bereit steht. Dazu wird einfach ein Archiv angelegt und darin alle nicht zwingend notwendigen Dateien (z.B. Protokolldateien) ausgeschlossen. Das erledigt ein klitzekleines Progrämmchen, was auch Archive nach 10 Tagen wieder löscht. Dadurch wächst der belegte Speicherplatz auch nicht ins Unendliche. Aufgrund eines aktuellen Anwenderwunsches habe ich dazu eine Anleitung erstellt und es unter Support/Extras/Backup abgelegt. Der große Vorteil für mich ist der problemlose Rückgriff auf einen älteren Stand ohne den Provider bemühen zu müssen. Auch wenn man einen Provider ohne Backup hat (gibt's das überhaupt?), kann man das selbst durch einfachen Download des Archivs durchführen. Dieser Artikel wurde veröffentlicht am 03.08.2009 um 08:35 Uhr. Noch kein Kommentar. Neue tdbengine für ewm5 Es gibt da ein gewisses Problem, bei manchen Serverkonfigurationen. Intern baut die tdbengine auf Freepascal auf. Dort gibt es eine Funktion, die aus einem Dateinamen diesem mit kompletten Pfad macht. Dabei scheint es einen Fehler zu geben, der entweder an Freepascal oder Linux selbst liegt. Das tritt aber nur bei bestimmten Serverkonfigurationen auf. In der Regel sind das Server von Providern, die Webspace vermieten und diesen bewusst einschränken. In der Praxis würde auf solchen Servern die tdbengine (und damit auch eforia) nicht richtig arbeiten. Deswegen hatte schon vor einigen Jahren Sergey eine Spezialversion gemacht, die intern etwas anders arbeitet und das Problem so umgeht. Nun war das eine einmalige Version, auf dem damaligen Quellcode-Stand. Für den ewm5 benötigt man aber eine aktuellere tdbengine. Nun war Sven so freundlich, diesen Fix in seinen tdbengine-Quellcode zu übernehmen. D. h. nun kann er eine solche Spezialversion immer einfach per Compileroption erzeugen. Deswegen gibt es jetzt auch eine solche auf dem aktuellen Stand. Download wie gewohnt unter Support/Download. VIELEN DANK an Sven. Wie wäre es, wenn jeder, der bei seinem Webspace diese Spezialversion benötigt, ihm eine kleine Dankesmail schickt? 8-) Dieser Artikel wurde veröffentlicht am 20.07.2009 um 08:14 Uhr. Noch kein Kommentar. Update zum Jubiläum Na sowas. Jetzt ist dieses Blog schon wieder 2 Jahre alt. Ein guter Anlass, um mal wieder ein kleines Update abzustellen. Diesmal wurde ein Fehler im neuen Viewer-Kern behoben. Den dürfte wahrscheinlich niemand bemerkt haben, aber theoretisch hätte es eben sein können. Außerdem ist das mit dem Baum nochmal etwas geändert. Die Blätterfunktion ist nun niemals in der ersten Ebene aktiv. Eigentlich dachte ich, ich mache das über eine INI-Datei steuerbar, aber in der Praxis wird es wohl sowieso immer so sein, wie es jetzt eben der Standard ist. Die größte Änderung ist eigentlich schon ein paar Monate alt. Ich habe das aber nun seit längerem für mich im Einsatz und bin recht zufrieden. Die Statistikfunktion "erkennt" Google-Referer und stellt diese gesondert dar. Außerdem ist die jeweilige Zielseite bei Referern integriert. D.h. man sieht sofort, wenn ein Besucher von einer anderen Seite kommt, auf welcher Zielseite er gelandet ist. Zu guter Letzt kann man die Statistik auch per RSS abfragen. Ich mache das, um im RSS-Reader sofort mitzubekommen, wenn irgendwo etwas ungewöhnliches passiert. Dazu im Feed-Reader die URL so eintragen: http://[Domain]/custprg/counter.prg?rss=[kennwort] oderhttp://[Domain]/custprg/counter.prg?rss=[kennwort]&daily=1 Im ersten Fall werden auch Daten des aktuellen Tages ausgegeben, im zweiten Fall immer nur komplette Tagesdaten, also ist quasi der Vortag immer der aktuellste Eintrag. Zum Tages/Monatswechsel gibt es dann immer noch eine Übersicht. Das Kennwort wird in der Datei ini/counter.ini festgelegt. Der Sinn dürfte klar sein. Es soll ja nicht jeder die eigenen Statiken abrufen können. Wobei der Aufruf mittels https dann natürlich auch zu bevorzugen wäre, außer man kann sicherstellen, dass die URLs nicht irgendwo abgehört werden können. Bei mir ist es eben so, weil Webserver und RSS-Reader auf dem gleichen Server laufen. Dieser Artikel wurde veröffentlicht am 13.07.2009 um 14:37 Uhr. Noch kein Kommentar. Zeige 21 - 30 von 102
|

Hier bloggt Horst Klier mit und über eforia web manager und was dazugehört (HTML, Javascript, Internet, Webdesign, Such- maschinenoptimierung, usw.).
>> Zur Blog Startseite abonnieren Übersicht über alle Beiträge |
|||||
| eforia® ist ein eingetragenes Markenzeichen. Alle anderen Marken und Markenzeichen gehören Ihren jeweiligen Besitzern. Letzte Aktualisierung dieser Seite: 27.07.2024 / 05:53:18 | ||||||

