

 Übersicht
Übersicht|
Ajax-Anwendungen und Google Lange Jahre bremsten Suchmaschinen wie Google die technische Weiterentwicklung im Web aus. Man musste Seiten bauen, die gut zu indizieren waren und zu viel Technik in Form von nachladenden Javascript-Anwendungen (bekannt als Ajax) waren einfach ein Problem. Doch seit wenigen Monaten gibt es eine Lösung. Google hat dazu den Hashbang auserkoren. Das ist die Kombination der beiden Zeichen #!. Die Raute (heute modern als "hash" bezeichnet) diente schon seit HTML 2.0 zur Kennzeichnung von internen Sprungzielen in Seiten. Wobei die Seite selbst dabei gleich blieb. Das nutzten Javascript Programmierer schon bald aus, um darüber verschiedene Zustände von Anwendungen zu speichern. Als Beispiel sei ein Forum genannt, dass auf einer Seite "board.html" liegt und mit Ajax entwickelt wurde. Die URL "board.html#forum123" könnte direkt benutzt werden, um das Forum "forum123" anzuzeigen. Nur Google weiß eben nichts davon und das Forum ist schlicht nicht zu finden. Da kommt nun der Hasbang ins Spiel. Benutzt man nicht "board.html#forum123" sondern "board.html#!forum123" kann Google damit umgehen. Intern wird dann die URL "board.html?_escaped_fragment_=forum123" abgerufen. Mit ein wenig mod_rewrite kann man nun seine Inhalte dem Google-Crawler zugänglich machen. Detail dazu finden sich bei Google hier [Link entfernt, weil Linkziel leider nicht mehr verfügbar] (sogar in deutsch). Wie nutzt man das in der Praxis? Ich bleibe bei meinem Beispiel, dem Forum. Mal angenommen, ich hätte ein Modul namens Board für eforia. Darin gibt es Routinen für eine Forumsliste, Forumsinhalt und Beitragsausgabe. Dazu noch interne Verwaltungssachen für Moderatoren, Antworten, Ändern, usw.. Das brauchen wir aber nicht, weil der Google Crawler kaum Beiträge verfassen wird. Bleiben also die 3 Funktionen Forumsliste, Forumsinhalt und Beitragsausgabe. Diese werden auf der Forumsseite per Ajax aufgerufen und liefern HTML zurück, der dann direkt in die Seite gesetzt wird. Dazu muss ein Script die URL mit Hashbang zerlegen, den passenden Aufruf erzeugen und entsprechend verarbeiten. Das Modul selbst erzeugt einfach die Ausgabe und liefert diese zurück. Und genau das nutzen wir doppelt. In cmsMain prüfen wir, ob Parameter über _escaped_fragment_ übergeben wurden, rufen dann intern eine der 3 Routinen auf und fügen die Ausgabe an Stelle des Spacers ein. So wie es eben bei eforia Modulen auch sonst erfolgt. Nochmal:
RewriteCond %{THE_REQUEST} /board.html [NC] RewriteCond %{QUERY_STRING} _escaped_fragment_.* [NC] RewriteRule ^board.html$ /programm/o.prg?lfd=9509&%{QUERY_STRING} [L] Das führt dazu, dass für den Crawler eben eine HTML-Version ohne Ajax ausgegeben wird. In diesem Beispiel ist die Seite mit dem Forum eben board.html und intern befindet sich das Modul auf der Seite mit der lfd=9509. Eine Kleinigkeit fehlt noch, um das zu aktivieren. Den Google weiß ja nicht, dass er (es?) bei "board.html" so vorgehen soll. Und jeden Link deswegen als "board.html#!" anzugeben wäre unschön. Aber auch daran wurde gedacht. Man fügt in die Seite <meta name="fragment" content="!"> ein. Das geht am Einfachsten in der Vorlage mit einer Bedingten Ausgabe: {if="'ajaxanwendungenundgoogle'='board'"}<meta name="fragment" content="!">{end} Und fertig ist eine schicke Ajax-Anwendung, die nebenbei noch perfekt von Google gecrawlt werden kann. Der Nerd in mir findet das einfach toll. Natürlich ist das Beispiel eines Forums nicht ganz zufällig gewählt. Das gibt es nämlich tatsächlich. Ich muss nur noch die Vorlagen überarbeiten und mit überlegen, wie das mit den Nutzerprofilen ist. Weil so richtig Spass macht es ja nur, wenn man auch Profilbilder anlegen kann. Aber wie das dann aussehen könnte, kann man schon mal hier [Link entfernt, weil Linkziel leider nicht mehr verfügbar] sehen. Dieser Artikel wurde veröffentlicht am 17.12.2010 um 16:37 Uhr. Noch kein Kommentar. eforia SEO gegen Typo3 Es gab mal eine Website, die wurde mit eforia web manager aufgebaut. Diese gab es recht viele Jahre, es wurde aber nie auch nur ein Cent in das Thema Suchmaschinenoptimierung investiert. Die Seite enthielt viele dynamische Bereiche die teilweise nur nach Login erreichbar waren. Also etwas, was ohne ein paar grundlegende Gedanken schwer Google schmackhaft zu machen ist. Aber trotzdem reichten die eforia Standardeinstellungen ganz gut aus. Im Oktober letzten Jahres sollte dann alles bunter und schöner werden. Die Seite wurde umgestellt auf Typo3. Das Resultat sieht man hier: 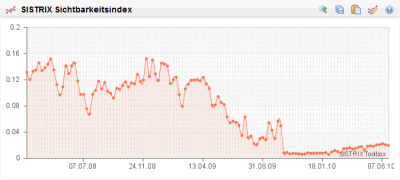 Bis heute, 8 Monate später, hat sich die Seite noch nicht erholt. Damit will ich nicht sagen, dass die Seite vorher toll Suchmaschinenoptimiert war. War sie nicht. An das Thema wurde nie ein Gedanke oder gar ein Cent (bzw. damals noch Pfennig) verschwendet. Auch will ich nicht sagen, dass man Typo3 Seiten nicht optimieren kann. Was ich sagen will ist, wenn man sich keine Gedanken darum macht, liegt eforia deutlich vorn. Der Screenshot stammt übrigens von der Sistrix Toolbox. Der Sichtbarkeitsindex berechnet anhand von Rankings für eine große Anzahl Schlüsselwörter einer Website einen Wert, der grob anzeigt, wie sichtbar eine Seite bei Google ist. Natürlich könnte man auch einfach die Besucherströme messen, aber diese schwanken durchaus. Der Sichtbarkeitsindex ist da wesentlich stabiler und gibt einen erstaunlich guten Überblick über die Optimierung einer Seite. Gerade größere Seiten kann man ohne solche Tools kaum vernünftig managen. Dieser Artikel wurde veröffentlicht am 28.06.2010 um 10:53 Uhr. Noch kein Kommentar. SEO-Tipp: 404 abfangen Heute mal ein kleiner SEO-Tipp und wie man diesen in der Praxis mit eforia umsetzt. Wie heutzutage jedem Webmaster bekannt sein dürfte, sind Links für eine gute Position bei den gängigen Suchmaschinen enorm wichtig. Dumm, wenn jemand die eigene Seite verlinkt, aber versehentlich einen Tippfehler in der Adresse hat. Ein beliebtes Problem sind Kommentare oder Foren, bei denen URLs automatisch in Links gewandelt werden, wenn man die Adresse in Klammern angibt. Also z.B. Ich benutze eforia als CMS (http://www.eforia.de/index.html)und die Software extrahiert als Link nicht http://www.eforia.de/index.htmlsondern http://www.eforia.de/index.html)Das Resultat ist ein "404 Not Found"-Fehler. Der Link ist verloren. Nun kann man die eigenen Webserver-Logfiles nach 404-Fehlern durchforsten. Das machen Techniker sicher auch gerne, aber wenn man keinen Zugriff darauf hat, gibt es auch eine andere Methode solche Seiten zu finden. Nämlich über die Google Webmaster-Tools. Hat man eine Seite dort angemeldet, findet sich unter dem Punkt Diagnose/Crawling-Fehler auch die Option Nicht gefunden. 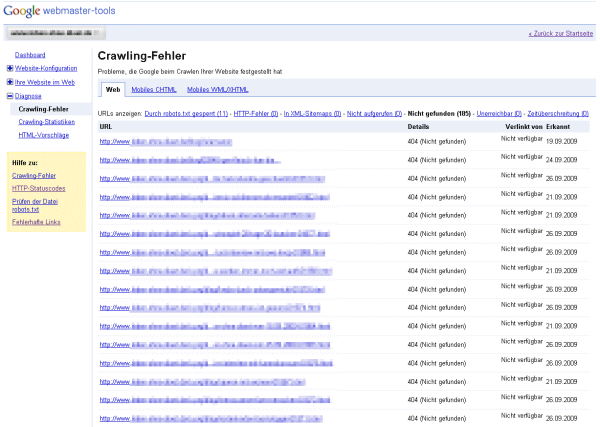 Dort erhält man eine Liste von Adressen, die Google versucht hat zu crawlen, aber nicht gefunden hat. Manchmal wird auch die Ursprungsseite angezeigt, dann könnte man sich evtl. an den Linksetzer wenden und um Korrektur bitten. Oft ist das aber nicht möglich. Deswegen legen wir selbst Hand an. Solange zumindest die Domain stimmt, kommen die Besucher ja zu unserer Seite. Wir müssen ihnen nur den Weg zeigen. Das geht mit einem Redirect ganz einfach. Wer einen Apache als Webserver verwendet - also im Prinzip jeder 8-) - kann über eine .htaccess-Datei Redirect-Regeln anlegen. Ich hatte darüber schon vor 2 Jahrenmal etwas dazu geschrieben. Tipp: Mit ewm5 kann man sich die Bearbeitung der .htaccess-Datei erleichtern. Einfach in der cms.ini unten anfügen: und schon kann direkt über Tools/Konfiguration/Editor für INI-Dateien auf die .htaccess zugegriffen werden.  Was schreibt man nun da rein?Ganz oben muss zuerst mal die sogenannte Rewrite-Engine gestartet werden. Das macht man mit einemDann kommen die einzelnen Regeln. Für das obige Beispiel mit der Klammer am Ende würde es z.B. so aussehen: Wenn man davon auch nichts versteht außer, dass die \ das jeweils nächste Zeichen maskieren - also es wird dann so verstanden wie es aussieht und hat keine Sonderfunktion, wie es ein . und eine ) sonst hätten - versteht man schon das Prinzip. Man kann mit regulären Ausdrücken arbeiten und z.B. so auch eine Regel erstellen, die alle ) am Ende entfernen würde. Davon rate ich aber eher ab. Das sollte nur in Einzelfällen gemacht werden, wenn sich das Problem anderweitig wirklich nicht beheben lässt. Zum Schluss noch ein Beispiel, für einen simplen Tippfehler in der URL. Die korrekte Adresse wäre http://www.eforia.de/blog/index.htmlaber jemand hat http://www.eforia.de/block/index.htmlverlinkt. Die RewriteRule muss dann so aussehen: Einfach, oder? Die Regeln werden übrigens einfach hintereinander geschrieben. Das ReWriteEngine on ist nur einmal notwendig. Man kann auch noch Bedingungen einfügen und auch mehr als nur 301er Weiterleitungen. Aber dafür gibt es jede Menge Stoff im Netz. Und bitte keine Panik, wenn es mal nicht auf Anhieb klappt. Selbst langjährige gestandene Programmierer haben immer wieder Probleme. Da muss man einfach mal ein wenig damit spielen, dann geht das schon. Wer Fragen hat, darf sich gerne an mich wenden. Ich habe doch schon etwas Erfahrung auch mit komplexeren Rewrite-Spielereien. 8-) Achja, das ist übrigens etwas, was Google einem nicht übel nimmt. Ganz im Gegenteil. Man verhindert damit ja eine Fehlermeldung beim Nutzer. Das verbessert dessen "Experience". Das findet Google toll! Dieser Artikel wurde veröffentlicht am 05.10.2009 um 14:04 Uhr. Noch kein Kommentar. Update zum Jubiläum Na sowas. Jetzt ist dieses Blog schon wieder 2 Jahre alt. Ein guter Anlass, um mal wieder ein kleines Update abzustellen. Diesmal wurde ein Fehler im neuen Viewer-Kern behoben. Den dürfte wahrscheinlich niemand bemerkt haben, aber theoretisch hätte es eben sein können. Außerdem ist das mit dem Baum nochmal etwas geändert. Die Blätterfunktion ist nun niemals in der ersten Ebene aktiv. Eigentlich dachte ich, ich mache das über eine INI-Datei steuerbar, aber in der Praxis wird es wohl sowieso immer so sein, wie es jetzt eben der Standard ist. Die größte Änderung ist eigentlich schon ein paar Monate alt. Ich habe das aber nun seit längerem für mich im Einsatz und bin recht zufrieden. Die Statistikfunktion "erkennt" Google-Referer und stellt diese gesondert dar. Außerdem ist die jeweilige Zielseite bei Referern integriert. D.h. man sieht sofort, wenn ein Besucher von einer anderen Seite kommt, auf welcher Zielseite er gelandet ist. Zu guter Letzt kann man die Statistik auch per RSS abfragen. Ich mache das, um im RSS-Reader sofort mitzubekommen, wenn irgendwo etwas ungewöhnliches passiert. Dazu im Feed-Reader die URL so eintragen: http://[Domain]/custprg/counter.prg?rss=[kennwort] oderhttp://[Domain]/custprg/counter.prg?rss=[kennwort]&daily=1 Im ersten Fall werden auch Daten des aktuellen Tages ausgegeben, im zweiten Fall immer nur komplette Tagesdaten, also ist quasi der Vortag immer der aktuellste Eintrag. Zum Tages/Monatswechsel gibt es dann immer noch eine Übersicht. Das Kennwort wird in der Datei ini/counter.ini festgelegt. Der Sinn dürfte klar sein. Es soll ja nicht jeder die eigenen Statiken abrufen können. Wobei der Aufruf mittels https dann natürlich auch zu bevorzugen wäre, außer man kann sicherstellen, dass die URLs nicht irgendwo abgehört werden können. Bei mir ist es eben so, weil Webserver und RSS-Reader auf dem gleichen Server laufen. Dieser Artikel wurde veröffentlicht am 13.07.2009 um 14:37 Uhr. Noch kein Kommentar. SEO-Tipp: Doppelte Inhalte Bei jedem Content Management System sind doppelte Inhalte (der SEO spricht von Duplicate Content, kurz DC) ein gewissen Problem für die Suchmaschinen-Position. Grob gesagt, können die gleichen Texte oft über unterschiedliche URL-Adressen erreicht werden. Eine Suchmaschine muss dann entscheiden, welche dieser bekannten Adressen die richtige ist. eforia bietet mit den statischen URLs und automatischen Umleitungen bereits gute Möglichkeiten, dieses Problem klein zu halten. Aber seit kurzem gibt es eine offizielle Methode, die von den großen Suchmaschinen unterstützt wird. Man kann gezielt angeben, welche Seite dort als Adresse benutzt werden soll. Dazu gibt es einen Link-Tag, der im Kopf der HTML-Seite zu benutzen ist. Mit der 5er Version ist es nun besonders einfach das zu nutzen. Man fügt schlicht den folgenden Code in die Haupt-Vorlage ein, den Rest erledigt eforia: <link rel="canonical" href="{link="url:full;type:static;"}" /> Auf diese Art wird die Suchmaschine angewiesen, immer die statische Variante zu bevorzugen. Dazu würde ich auch dringend raten. Schon allein, weil die URL so genau bestimmt werden kann und der Suchende schon darüber Informationen bekommt, wo er landen wird. Dieser Artikel wurde veröffentlicht am 03.03.2009 um 09:00 Uhr. Noch kein Kommentar. Website umstrukturieren und alte URLs retten Öfter kommt es vor, dass man eine Website neu gestaltet und das auch mit einer Neuordnung der Inhalte einher geht. Dabei ändert sich nicht nur die Navigation, sondern daraus in Konsequenz die Adressen der Seiten - die URL. Besonders wenn man eine bestehende, bisher manuell erstellte, Seite erstmals mit einem CMS umsetzt, geschieht das oft mit einer Umstrukturierung der Inhalte. Seiten werden verschoben, zusammengefasst, entfernt und neu erstellt. Doch was macht man mit all denen, die eine der alten Adressen als Lesezeichen im Browser gespeichert haben? Oder wenn auf einer anderen Website ein Link zu einer alten Seite steht? Sollen die Besucher dann eine unschöne Fehlerseite angezeigt bekommen? Das muss nicht sein. Die eleganteste Lösung ist eine Weiterleitung zur neuen Adresse. Beispiel: Bisher gibt es eine Seite /sofindensieuns.html. Im neuen Auftritt wird die Seite /kontakt/anfahrt.html sein. Nun wird der Webserver angewiesen, beim Abruf von /sofindensieuns.html auf die neue Adresse weiterzuleiten. Als Weiterleitungscode wird 301 benutzt. Das bedeutet "Moved Permanently", also die Adresse wurde dauerhaft (permanent) geändert. Eine solche Weiterleitung kann der Apache-Webserver mit installiertem mod_rewrite ausführen. Man muss nur eine Datei mit dem Namen .htaccess anlegen, in der spezielle Anweisungen stehen. Für obiges Beispiel würde das so aussehen: RewriteEngine on RewriteRule ^(sofindensieuns\.html)$ /kontakt/anfahrt.html [R=301] Wichtig ist bei der Ursprungs-Adresse der \. statt einem einfachen .. Es können nämlich die sogenannten regulären Ausdrücke benutzt werden und der Punkt hätte dann eine spezielle Bedeutung. Also muss er maskiert werden, was durch den vorgestellten \ geschieht. Ansonsten ist es doch einfach, oder? Beispiel 2: Alt:
Bitte fragen Sie jetzt nicht nach den Sinn des Beispiels, aber es passt ja zur Adventszeit. 8-) Es existieren also bisher zwei Seiten, die nun zu einer Neuen zusammengefasst werden sollen. Auch das ist ohne weiteres möglich. Man leitet einfach die beiden alten Adressen auf eine neue Zielseite um: RewriteEngine on RewriteRule ^(rezept/lebkuchen\.html)$ /weihnachten/backen.html [R=301] RewriteRule ^(rezept/butterplaetzchen\.html)$ /weihnachten/backen.html [R=301] Wie Sie sehen, muss das RewriteEngine on nur einmal angegeben werden. Also "einfach" eine Liste aller alten Dateien machen, den passenden neuen Inhalt suchen und für jede alte Seite eine Weiterleitung zur entsprechenden neuen Seite einrichten. Das ist unter Umständen eine menge Arbeit. Aber Ihre Besucher werden es Ihnen danken. Suchmaschinen natürlich auch. 8-) Hinweis: Der Artikel wurde inspiriert durch eine konkrete Anfrage eines Kunden, der seine bisherige Frontpage-Seite nun auf eforia umstellt. An dieser Stelle schöne Grüße und guten Flug. 8-) Dieser Artikel wurde veröffentlicht am 12.12.2007 um 15:29 Uhr. Noch kein Kommentar. Interne Verlinkungen Im Alinki-Blog [Link entfernt, weil Linkziel leider nicht mehr verfügbar] gibt es einen sehr lesenswerten Artikel über Site-Interne-Linkstrukturen. Bleibt anzumerken, dass solche Gedanken nicht nur für Suchmaschinen wichtig sind, sondern vor allem auch für Besucher. Nach Möglichkeit sollte man von jeder Seite mit zwei Klicks zu jeder anderen Seite kommen. ewm bietet Module für die erwähnte Brotkrumen-Navigation. Themenspezifische Verlinkung ist manuell oder automatisiert beispielsweise mit TagMagic möglich. Je nach Struktur kann auch ein Submenu oder Overview helfen. Wobei letzteres auch für neue Elemente gut geeignet ist. Als Beispiel kann die Anzeige der letzten Blogbeiträge auf der Startseite dienen. Im Artikel nicht erwähnt, aber immer sehr, sehr empfehlenswert ist eine simple Sitemap. Wenn diese in der Navigation auf jeder Seite angeboten wird, kommt der Benutzer bereits mit zwei Klicks auf jede andere Seite. Ich gehe sogar noch soweit, dass ich z. B. eine extra Übersichtsseite für die Blog-Beiträge benutze. Und soll ich ehrlich sein? Die benutze wahrscheinlich ich selbst am öftesten, wenn ich einen alten Artikel suche. 8-) Dieser Artikel wurde veröffentlicht am 03.11.2007 um 19:25 Uhr. Noch kein Kommentar. ewm5 Beta Update Ein neues Update, mit ein wenig Feinschliff:
Dieser Artikel wurde veröffentlicht am 09.10.2007 um 11:37 Uhr. 2 Kommentare. Suchmaschinenoptimierung mit ewm Sistrix erklärt sehr gut [Link entfernt, weil Linkziel leider nicht mehr verfügbar], die verschiedenen Schichten der Suchmaschinenoptimierung. Das möchte ich zum Anlass nehmen, zu erklären, was ich meine, wenn ich sage, dass man mit ewm sehr gut suchmaschinenoptimierte Seiten erstellen kann. Damit ist vor allem das gemeint, was Sistrix als Fundament beschreibt. Das geht nicht von selbst, ist aber möglich. Im Prinzip muss man nur die statischen Seiten nutzen. Ein wenig Gedanken zum Quelltext, saubere Überschriften und alle wichtigen Seiten mit möglichst wenigen Klicks erreichbar machen und die Grundlage zur zweiten Stufe ist bereits gelegt. Ab dann, kann eforia nichts mehr tun. Der Rest ist die Sache der richtigen Inhalte und deren Strukturierung. Die dritte Stufe ist dann sowieso von außen bestimmt. Offpage-Faktoren, würde der SEO wohl dazu sagen. Dieser Artikel wurde veröffentlicht am 05.10.2007 um 11:32 Uhr. Ein Kommentar. Dynamische URL auf statische umlenken Zur Zeit ist es ja ziemlich ruhig hier. Das liegt daran, dass ich ein paar Änderungen angefangen habe, aber noch nicht ganz damit fertig bin. Also mit dem meisten schon, aber eben nicht mit allem. Außerdem habe ich nun noch ein paar Tage Urlaub um einen Vortrag vorzubereiten. Ich schätze mal so richtig weiter geht es erst ab ca. 20.9. Aber eine Kleinigkeit habe ich doch. Das mod Rewrite vom Apache wird immer gern genutzt, wenn man Serveranfragen intern an eine andere Adresse weiterleiten muss. Der Umgang mit den Anweisungen RewriteCond und ReWriteRule ist garnicht so einfach. Ich verzweifle immer wieder aufs neue, schaffe aber dann doch irgendwie, was ich will. Ich glaube auch, so geht es den meisten die es einsetzen. Das Internet ist voll mit Fragen und Antworten zum Thema. Gerade in der SEO-Szene gibt es auch viele Anleitungen denen man anmerkt, dass der Autor sich selbst zwar irgendwie helfen konnte, aber so richtig blickt er's auch nicht. Wie auch immer. Die heutige Aufgabenstellung ist folgende: Eine ewm Seite wird bisher mit http://www.irgend_was.de/programm/o.prg?pos=3.2 aufgerufen. Der Webmaster entscheidet sich nun, doch eine statische Seite dafür anzulegen. Diese ist http://www.irgend_was.de/text/katalog/regen.html. Nun hat aber die alte dynamische Adresse schon eine Weile existiert (und tut es ja noch). Zahlreiche andere Seiten haben diese auch so verlinkt. Nun ist es aber durchaus sinnvoll, sich möglichst auf eine einzige Seite zu konzentrieren. Daher will der Webmaster nun alle Aufrufe der alten Adresse auf die neue umleiten. Die Umleitung soll mit einem 301er statt finden. Das ist der Servercode, der für ständige Umleitung steht. Also wenn jemand die alte Adresse aufruft, bekommt er die neue Adresse mitgeteilt und die Information, dass in Zukunft nur noch die neue Adresse gelten soll. Es gibt auch noch den Code 302, der für einen temporären Umzug steht. Der Webmaster macht also nun eine .htaccess-Datei und erstellt folgende Regel: RewriteEngine on RewriteRule ^programm/o.prg?pos=3.2$ /text/katalog/regen.html [L,R=301] Und Pustekuchen. Das funktioniert nicht. Die Rewrite-Engine unterscheidet nämlich URI und Query sehr genau. Alles was nach dem Fragezeichen kommt, kann also in der ReWriteRule gar nicht mehr abgefragt werden. Die Lösung sieht dann so aus: RewriteEngine on RewriteCond %{QUERY_STRING} ^pos=3.2$ RewriteRule ^(.*)$ /text/katalog/regen.html? [L,R=301] Es wird also zuerst der Query-String geprüft und dann die eigentliche Regel erstellt. In diesem Fall wird nicht einmal mehr auf o.prg geprüft. Ich leite einfach alles um, was mit pos=3.2 aufgerufen wird. 8-) Das Fragezeichen am Schluss der Regel verhindert, dass der Query-String wieder angehängt wird. Das macht sonst mod Rewrite. Wenn man eigene Parameter in der Umleitung hat und trotzdem die Ursprungs-Query benötigt, muss man die Option QSA mit in die eckige Klammer setzen. Aber das würde hier schon wieder zu weit führen. So, mehr wollte ich heute garnicht sagen. Besteht den generell Interesse an Beispiele für mod Rewrite? Das Ding ist echt mächtig. Man kann z. B. beim Aufruf einer Seite die nicht existiert diese erst durch ein Script generieren lassen und dann ausliefern. Spannend, oder? In der Praxis setzt man mod Rewrite viel in der Suchmaschinenoptimierung ein um doppelte Inhalte zu vermeiden. Bei Interesse, kann ich noch eine Reihe Beispiele liefern. Dieser Artikel wurde veröffentlicht am 03.09.2007 um 14:44 Uhr. 2 Kommentare. Zeige 1 - 10 von 12
|

Hier bloggt Horst Klier mit und über eforia web manager und was dazugehört (HTML, Javascript, Internet, Webdesign, Such- maschinenoptimierung, usw.).
>> Zur Blog Startseite abonnieren Übersicht über alle Beiträge |
|||||
| eforia® ist ein eingetragenes Markenzeichen. Alle anderen Marken und Markenzeichen gehören Ihren jeweiligen Besitzern. Letzte Aktualisierung dieser Seite: 27.07.2024 / 15:37:43 | ||||||

